Tavus
API-first conversational video AI for real-time face-to-face agents
Last reviewed 2026-06-20
Tavus is an API-first platform for building real-time conversational video AI: AI humans (digital replicas) that see, hear, and talk face to face on video. Its Conversational Video Interface (CVI) unifies speech, perception, dialogue, and real-time rendering behind a single API, so developers can drop a humanlike video agent into a product, website, or app with a few lines of code. It is built on Tavus's own models (Phoenix for rendering, Raven for perception, Sparrow for turn-taking). Tavus targets developers and product teams who want a video front-end for an LLM (onboarding, support, coaching, tutoring, sales, healthcare intake), plus enterprise teams via white-label deployments. It is bring-your-own-LLM and OpenAI-compatible, so the conversation logic and knowledge stay in the customer's stack while Tavus handles the real-time avatar, perception, and timing. A human still designs the agent, supplies the LLM and knowledge, and reviews behavior, so it is best described as a supervised agent rather than an autonomous one.
What it can do
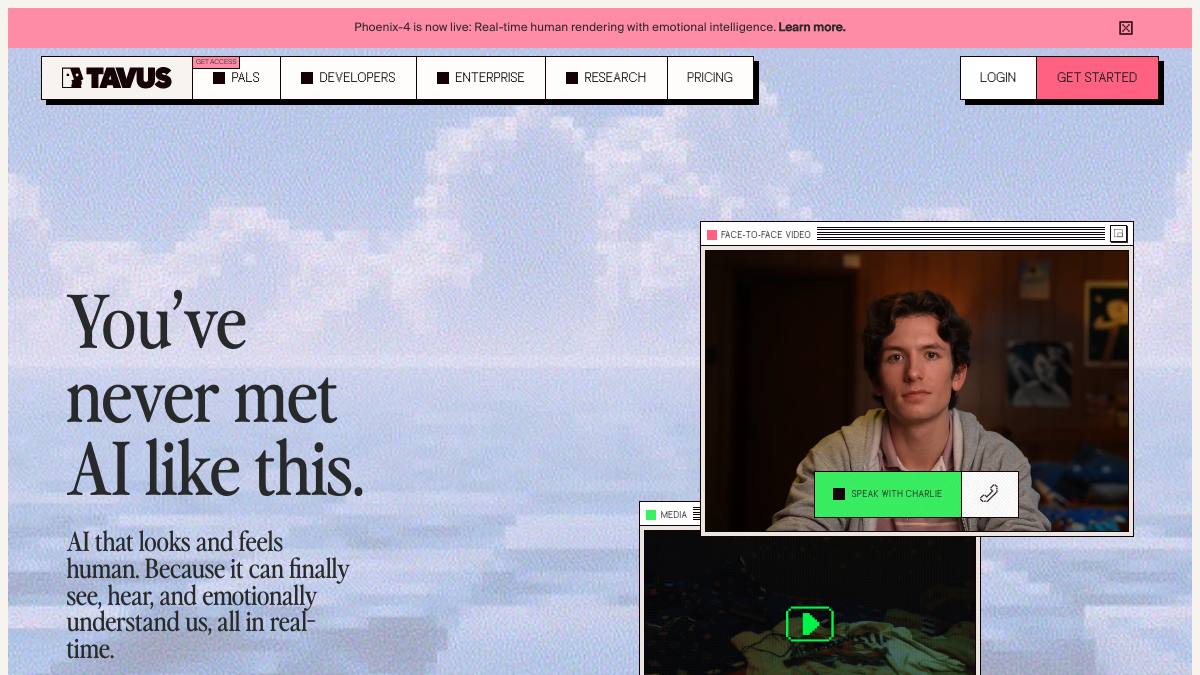
Real-time conversational video agents (CVI)
SupervisedThe Conversational Video Interface gives developers an out-of-the-box video agent that unifies speech, perception, dialogue, and rendering in one API, reportedly at roughly 600ms speech-to-video latency.
sourceReal-time avatar rendering (Phoenix model)
AssistantTavus's Phoenix rendering model produces full-face animation with lip-sync and micro-expressions; the company states 1080p full-face rendering at 40+ FPS.
sourceVisual and audio perception (Raven model)
SupervisedThe Raven perception model analyzes facial expressions, tone, gaze, emotion, and ambient environment in real time, and can trigger tools from visual or audio events.
sourceTurn-taking and interruption handling (Sparrow model)
AssistantThe Sparrow model handles natural pauses, interruptions, and conversational timing for smoother back-and-forth speech.
sourceCustom digital replicas
AssistantBuilds a custom AI human (replica) from roughly two minutes of video, alongside 100+ stock replicas, in 30+ to 50+ languages per Tavus's materials.
sourceBring-your-own-LLM, function calling, RAG, and memory
SupervisedCVI is OpenAI-compatible and bring-your-own-LLM, with function calling, RAG knowledge bases, cross-session memory, and a data layer of transcripts, emotion timelines, and perception events.
source
Strengths
- +API-first and bring-your-own-LLM, so the conversation logic and knowledge stay in your stack
- +Low-latency real-time video (reportedly ~600ms speech-to-video) with perception and turn-taking, not just lip-sync
- +Generous free tier and a clear usage-based ladder priced on conversational minutes
Limitations
- −Minutes-based usage pricing can climb quickly for high-volume, always-on agents
- −It supplies the video front-end, not the agent's reasoning, so you still build and own the LLM and knowledge
- −Realistic talking-head agents raise consent and deepfake concerns that need policy guardrails
Overview
Tavus builds the real-time conversational video layer for AI: AI humans (digital replicas) that see, hear, and talk face to face on video. Its flagship product, the Conversational Video Interface (CVI), is API-first and unifies speech, perception, dialogue, and rendering behind a single API so developers can embed a humanlike video agent in a product or app. Tavus is a Y Combinator company headquartered in San Francisco.
What it does
CVI runs on Tavus's own models: Phoenix for real-time full-face rendering (Tavus states 1080p at 40+ FPS with lip-sync and micro-expressions), Raven for visual and audio perception (facial expressions, tone, gaze, emotion, ambient environment), and Sparrow for turn-taking, interruptions, and conversational timing. Tavus reports roughly 600ms speech-to-video latency. Developers bring their own LLM (the platform is OpenAI-compatible) and get function calling, RAG knowledge bases, cross-session memory, and a data layer of transcripts, emotion timelines, and perception events. Custom replicas can be trained from about two minutes of video, alongside 100+ stock replicas across many languages.
Integrations & setup
Tavus is shipped as a REST API with an OpenAI-compatible LLM interface and an @tavus/react-cvi npm package; Tavus markets a roughly ten-line integration. It deploys on the customer's own infrastructure (the docs reference Vercel, AWS, or custom) and offers white-label enterprise options. Tavus states SOC 2, HIPAA, and GDPR compliance.
Pricing
Freemium and usage-based on conversational minutes. Developer plans: Basic (free, 25 minutes, 25 stock replicas), Starter $59/mo (100 minutes, 3 custom replica trainings/mo), Growth $397/mo (1,250 minutes, 7 custom replica trainings/mo), and custom Enterprise with unlimited replicas and volume discounts. Paid plans add pay-as-you-go overages. Separate consumer-style PALs plans (Free, Plus $20/mo, Max $50/mo) cover personal voice and video calls.
Traction
Tavus raised an $18M Series A led by Scale Venture Partners (with Sequoia, Y Combinator, and HubSpot) in 2024, and in November 2025 announced a $40M Series B led by CRV, bringing total funding to roughly $64M per secondary sources. Tavus's own materials cite figures such as 2B agent interactions; those are vendor-reported.
Best for / not for
Best for developers and product teams that already have an LLM and want to add a real-time, perceptive video face to it (onboarding, support, coaching, tutoring, healthcare intake), and for enterprises that want a white-label conversational video layer. Less suited to teams that want a finished, scripted marketing-video tool (HeyGen, Synthesia) or that want the agent's reasoning and knowledge handled for them.
Alternatives
HeyGen and Synthesia are the closest avatar-video competitors but lean toward pre-scripted rendering; D-ID also offers conversational video agents. For voice-only real-time agents, ElevenLabs Agents and Bland AI are adjacent.
What people are saying
We aggregate real LinkedIn discussion into sentiment for the agents people search most. Tavus isn't tracked yet, want it added? Request tracking.
FAQ
What is Tavus's Conversational Video Interface (CVI)?+
CVI is Tavus's API-first product for real-time conversational video: it bundles speech, visual/audio perception, dialogue timing, and real-time avatar rendering behind one API so developers can add a face-to-face AI video agent with a few lines of code.
Is Tavus autonomous?+
No. Tavus provides the real-time video, perception, and turn-taking layer; the reasoning comes from a bring-your-own LLM, and a human designs the agent and supplies the knowledge. It is best described as a supervised agent.
How is Tavus different from HeyGen or Synthesia?+
HeyGen and Synthesia focus mostly on rendering pre-scripted avatar videos. Tavus focuses on real-time, two-way conversational video agents that perceive and respond live, exposed as a developer API.
Sources
- Tavus CVI (official product page) · accessed 2026-06-20
- Tavus (official site) · accessed 2026-06-20
- Tavus pricing (official) · accessed 2026-06-20
- Generative AI video startup Tavus raises $18M (TechCrunch) · accessed 2026-06-20
- Tavus Raises $40M Series B (Business Wire) · accessed 2026-06-20
- Tavus (Y Combinator profile) · accessed 2026-06-20
Last reviewed 2026-06-20